
2章 機械学習のしくみを理解しよう 〜糖尿病と乳がんのデータ
石丸美穂,須藤毅顕
(東京医科歯科大学統合教育機構教学IR部門)
 教師あり機械学習の回帰とは
教師あり機械学習の回帰とは
教師あり機械学習の中でも最もシンプルな「回帰」を,Pythonで実践してみましょう.回帰とは,正解データと特徴量データを,回帰式という統計的モデルに当てはめて予測を行う解析方法です.ここで言う統計的モデルとは,大量のデータに内在する構造的な関係を指します.基本的な回帰モデルである線形回帰では,以下のような計算式がモデルとして設定されます.
y=β_{0}+β_{1}×x_{1}+β_{2}×x_{2}+ ... +β_{n}×x_{n}
yは正解データで,x_{1}〜x_{n}がn個の特徴量です.β_{0}は切片で,定数項です.β_{1}〜β_{n}はそれぞれの特徴量x_{1}〜x_{n}とyの関係を示す値であり,係数(偏回帰係数)と呼ばれます.特徴量に係数を掛けたものを特徴量の数だけ足し合わせ,一定の値を加えたものを正解データとする考え方です.係数や定数項はこの後も出てきますので,少し頭に入れておいてください.なお,特徴量が1つの場合の回帰を単回帰と呼び,回帰式は以下のような単純な1次関数(直線)の式となります.
y=β_{0}+β_{1}×x_{1}
このように,あるxとyのデータを直線の回帰式に近似させる方法を,線形回帰と呼びます.
 線形回帰を実践してみよう
線形回帰を実践してみよう
それでは,ここからは実際にColabを使って,教師あり機械学習を実践していきます.2章-3では,分かりやすい線形回帰から実践します.
具体的には,糖尿病のデータセットを用いて以下のステップで行います.一つ一つのステップを確認しながら,コードを実行していきましょう.
STEP[線形回帰の実践]
⓪事前準備
①データの用意
②学習モデルの選択
③データを入れて学習
④傾き(偏回帰係数)と切片(定数項)を推定
⑤未知の特徴量xで予測
⑥モデルの評価
 事前準備
事前準備
まずは,演習データDLサイト(➡p.12参照)からダウンロードした2章のノートブック(chap2.ipynb)をColabで開き,次のコードを実行します.
「!pip install …」はColabにインストールされていないパッケージを利用するときに使います.今回は日本語で図を書くためのパッケージである「japanize-matplotlib」をインストールします.その後,
 データの用意
データの用意

scikit-learn(サイキットラーン,Pythonのコード上ではsklearnと書きます)は,Pythonで利用できるデータ分析や機械学習のためのライブラリの一つです.load_diabetesはsklearnライブラリに含まれるdatasetsモジュールにある,diabetes(糖尿病)のデータを読み込むための関数です.モジュールに含まれる関数だけを利用できるようにしたいときは,「from ライブラリ名.モジュール名 import 関数名」を実行します.
今回はdmという変数に,「load_diabetes( … )」で読み込んだ糖尿病のデータセットを格納します.load_diabetes関数には,「as_frame=True」と「scaled=False」のとおり,2つのTrue(真)/False(偽)で指定します.「as_frame=」でTrueを指定するとpandasのデータフレーム型で,Falseを指定するとNumPy配列(➡5章p.156参照)でデータが読み込まれます.今回は,データフレーム型の方が扱いやすいため,Trueを指定します.「scaled=」でTrueを指定すると正規化された値で,Falseを指定すると生データの値で読み込まれます.正規化とは,データに対して何らかの計算を行い,すべてのデータを0~1の間の大きさにすることです(➡正規化は5章p.170でも取り上げています).機械学習では,正規化されている方が予測精度が高くなることが多いのですが,今回は分かりやすさを重視して生データのまま用いるため,Falseを指定します.
それでは,このデータセットを格納したdmの内容を見ていきましょう.
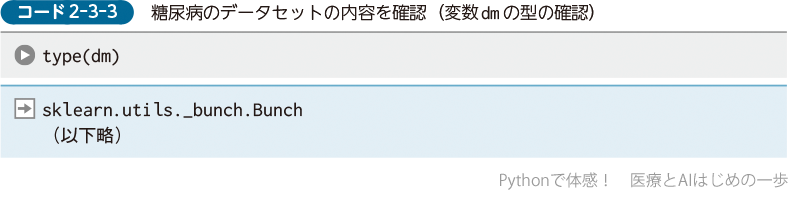
読み込んだdmの型を調べるため,「type(変数名)」を実行します.dmに格納した糖尿病のデータセットは,Bunch型というdictionary(辞書)型の一種になっています.辞書型は1章-2-3でも触れたように,
dataset = {'key1':'a', 'key2':'b', 'key3':'c', …}
等で作成される型です.辞書型は順序づけたキーと値の集まりであり,key1,key2,key3,…がキー,a,b,c,…はそれぞれのキーと紐づいて格納された値です.「データ名.キー」を実行することで,格納したデータの値を呼び出すことができます.
次に,dmのデータ自体を出力し,どのようなデータであるかを確認します.コード2-3-4とコード2-3-5を順番に実行してみましょう.

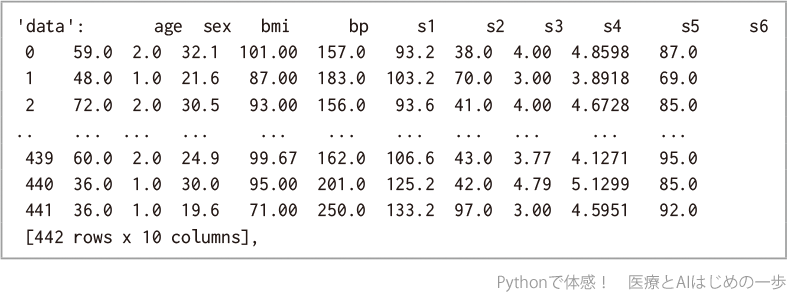
コード2-3-3で調べたように,型はBunch型であり,コード2-3-4で調べたように,キーとデータの組み合わせが複数入っています.キーとして,'data','target','DESCR','feature_names'などがあり,キーの後にそれぞれのキーと紐づいたデータが格納されています.以下の部分では,キーが'data',その後のage列〜s6列で0〜441行のデータフレーム(442行×10列)が,データ内容として入っています.
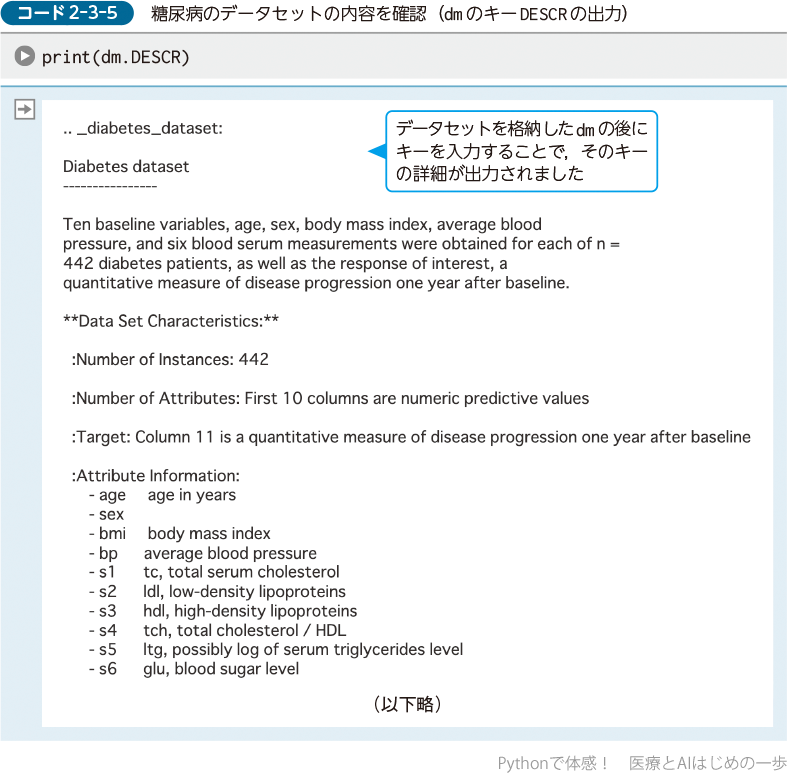
dmのキーDESCRには,データセットの詳細な情報が格納されています.「print()」を使うことで見やすい形で出力されます.
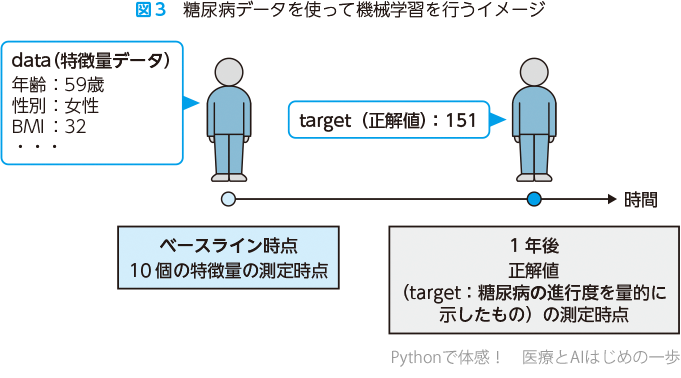
「Ten baseline variables …」の段落では,今回用いるdiabetes(糖尿病)のデータセットの説明として,次のとおり書かれています.「442人の糖尿病患者から得られた,ベースライン(基準)時点での10種類の変数(年齢,性別,BMI,平均血圧,および6個の血清測定値)の値と,興味がある変数(正解値のこと)として,ベースライン時点から1年後の糖尿病の進行度を定量的に示した指標」.
また,その下の「**Data Set Characteristics:**」には,データセットの特性が表示されています.補足すると次のとおりです.
- Number of Instances(データの行数)は442人です.
※ここでの「Instances」はPythonにおける「クラス」の「インスタンス」とは異なる意味です. - Number of Attributes(属性の数)は10で,数値型の値です.
- Target(正解の値)は,ベースライン時点から1年後の糖尿病の進行度です.
- Attribute Information(属性の情報)には,10個の属性の内容が記載されています.age(年齢),sex(性別),bmi(体格指数),bp(平均血圧),s1はtc(総血清コレステロール値),s2はldl(LDLコレステロール),s3はhdl(HDLコレステロール),s4はtch(総コレステロール/HDL),s5はltg(log(血清トリグリセミド)),s6はglu(血糖値)です.
ここで糖尿病データでの解析デザインのイメージを図3に示します.ベースライン時点で,特徴量のデータを442人の患者から取得しています.その人たちに対し,ベースライン時点から1年後の糖尿病の進行度を評価しています(研究における測定開始時点をベースラインと呼びます).したがって機械学習を行うには,特徴量(data)と正解値(target)のデータをそれぞれ準備する必要があります.
ではまず,データセットを格納したdmから正解値を取り出して内容を確認していきましょう.

